想把 Ulysses 的文章批量导出为 Markdown(用来备份或迁移),看似简单(Ulysses 自身提供了丰富的导出选项),但只要尝试一下就会发现并非易事。
如果选择导出为 Markdown,我们会得到如下文件结构的文件:
/
├── index.md
├── image1.jpg
└── image2.jpg
└── ...
index.md 是我们选择的所有文章,是的,Ulysses 会把我们的所有文章变成一个 Markdown 文件,而不是每篇文章一个 Markdown 文件。
我们也可以不用 Ulysses 提供的导出,而选择手动导出:
- 在 Ulysses 软件设置【边栏】,勾选「外部文件夹」
- 在 Ulysses 外部文件夹新建任意名的文件夹
- 把 Ulysses 的多篇文章拖到新建的文件夹,即会保存成独立的 Markdown 文件
这种方式也不完美,因为图片并不会拷贝过去,导致保存的 Markdown 文章内图片链接失效。
另一种方法是用 Ulysses 导出为 TextBundle ,这是一种打包 Markdown 及其相关资源的文件格式,由 Ulysses 的开发团队和一些 Markdown 编辑器开发者一起制定,目的就是解决 Markdown 文件传播时内嵌资源(比如图片)丢失的问题。Ulysses、iA Writer、Bear 等编辑器都支持 TextBundle 的文件交换。
TextBundle 文件本质上就是一个压缩打包。用 Ulysses 导出文章合集的 .textbundle 文件的默认目录结构如下:
20250813.textbundle
├── text.md
├── info.json
└── assets/
├── image1.jpg
├── image2.png
├── ...
Ulysses 仍会把多篇文章合并成一个 Markdown(这里是 text.md),assets 目录下是所有图片。
我们可以写一个脚本(比如用 Python)把 text.md 按照一级标题 # 拆分成多篇 Markdown 文件,并把一级标题作为文件名。
脚本我可不会写,不过有 AI,这都不算事儿。
新建一个 .py 文件,文件名叫比如 split_textbundle.py,粘贴如下代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import shutil
import re
def sanitize_filename(name):
return re.sub(r'[\/:*?"<>|]', "_", name)
def split_textbundle(bundle_path, output_dir):
markdown_file = os.path.join(bundle_path, "text.md")
if not os.path.isfile(markdown_file):
print(f"未找到 {markdown_file}")
return
os.makedirs(output_dir, exist_ok=True)
with open(markdown_file, "r", encoding="utf-8") as f:
content = f.read()
# 按一级标题拆分
parts = re.split(r'(?m)^# (.+)', content)
for i in range(1, len(parts), 2):
title = parts[i].strip()
body = parts[i+1].strip()
filename = sanitize_filename(title) + ".md"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as out_f:
out_f.write(f"# {title}\n{body}\n")
print(f"保存: {filepath}")
# 复制 assets 文件夹
assets_src = os.path.join(bundle_path, "assets")
if os.path.isdir(assets_src):
assets_dst = os.path.join(output_dir, "assets")
if os.path.exists(assets_dst):
shutil.rmtree(assets_dst)
shutil.copytree(assets_src, assets_dst)
print(f"复制 assets 文件夹到 {assets_dst}")
def main():
# 获取当前脚本所在目录
current_dir = os.path.dirname(os.path.abspath(__file__))
# 找到目录下唯一的 .textbundle 文件
bundle_files = [f for f in os.listdir(current_dir) if f.endswith(".textbundle")]
if len(bundle_files) != 1:
print("请确保目录下只有一个 .textbundle 文件")
return
bundle_path = os.path.join(current_dir, bundle_files[0])
output_dir = os.path.join(current_dir, "split_output")
split_textbundle(bundle_path, output_dir)
print("拆分完成!Markdown 文件已生成在 'split_output' 文件夹中。")
if __name__ == "__main__":
main()把导出的 xxx.textbundle 和 split_textbundle.py 这两个文件放在同一个文件夹内,且目录下只有这两个文件。
打开终端,进入文件夹,运行脚本:
python3 split_textbundle.py脚本会自动生成一个 split_output 文件夹,里面包含每篇文章的 Markdown 文件,并复制 assets 文件夹。
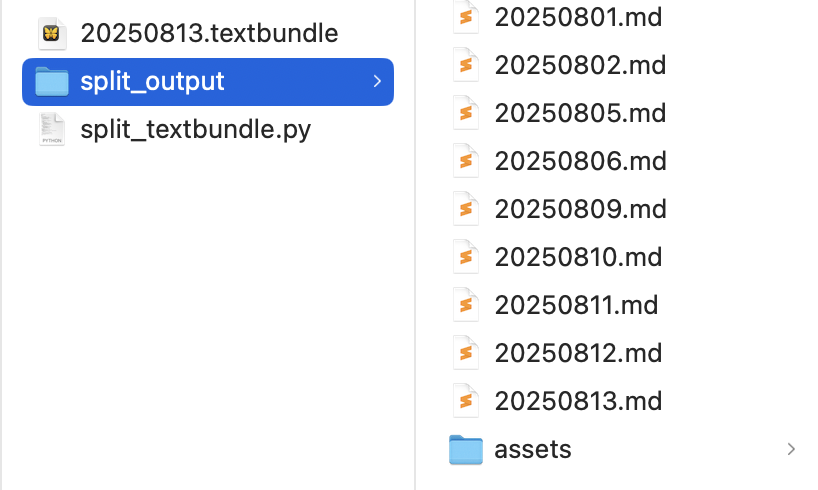
现在我们可以把 split_output 文件夹里的所有文件——包括 Markdown 文章和图片——备份到别的地方,或者迁移到 Typora、Obsidian 等你喜欢用的其他 Markdown 编辑写作工具。
添加 Front Matter Title
另外两个不太完美的脚本方案
https://github.com/kevboh/export-ulysses https://dev.to/emma/how-to-export-from-ulysses-to-markdown-13pi
Obsidian 的 Importer 插件 可以把 .textbundle 导入到 Obsidian 中,但依然无法拆分文章。